
昇腾集群部署DeepSeek疯狂踩坑
Published:
接到给学校部署DeepSeek模型的任务,终于部署起来了,发现还是挺好用的。最近任务紧,等过几天闲下来不断完善踩坑记录。
原先的吐槽
接到辅助学校部署DeepSeek的任务,很急。现在是凌晨1:10,是什么,让我忍不住要写这个笔记,我实在绷不住了啊!!!
魔乐社区的奇妙体验
我真傻,真的,我只知道魔乐社区下载很快,我只知道魔乐社区是华为推出的,应该很兼容,不知道这是一个多大的坑。
- 魔乐社区下载工具不支持python3.11,但是华为MindIE官方镜像里的python是3.11
- 有人说,你装个python3.10不就行了吗?但是对不起,系统是华为自己的OpenEule,要装python自己编译。这任务火烧眉毛了还自己编译python呢.
- 有人说,你为什么不在宿主机下载,映射到容器里?我试了,魔乐社区的工具虽然下载到目标目录里,但是大文件是个软连接,都存储在
~/.cache下,我在容器里根本读取不到。我好不容易配置好了容器还得重启一个改映射?? - 有人说,他不是还支持git吗。很好,他需要git lfs。但是openeuler仓库的git-lfs没有引入到主线版本和正式版本中,只能自己找源码编译。
一切都回来了,想用的话,正反都要自己编译个软件先。
不是,我真的第一次见指定了目标下载地址,竟然给我整了个指向home目录的软链接?我要是home目录磁盘小了还装不下了???P.S. 后来补充,`~/.cache`软链接里面像乱码的文件夹里有模型文件,可以自己写个脚本批量复制出来。
双机直连好多坑
我们搞了个两台昇腾服务器直连,显卡互相之间访问,这应该是最快的方法吧,就想着能算的快一点,大家用户体验好一点。
但是完全没想到的是,昇腾的多机多卡部署竟然需要每个显卡必须配置网关,直连根本没有网关。不是,你都能直连了,传就是了为啥要设置网关啊!!
程序不语,只是一味的报错。我真傻,真的。
P.S. 后来补充,后面解决了,看下面的记录。
时灵时不灵的自动部署工具
本来我是想直接部署 MindCluster的,结果 A900T 在 OpenEuler_22.03LTS-SP4 上不支持ascend-deployer自动部署,给我整晕了,服务器是华为的、系统是华为的、部署工具也是华为的,加在一起咋不能用了……
MindIE系统配置调优
具体分析见下文的 《相关概念和调度策略分析》 章节。部分参数参考于昇腾论坛博客。
调度参数:这两个参数管理了Prefill和Decode的优先选择,他们会通过公式比较大小来调度,建议固定其中一个,然后修改另一个就可以
prefillTimeMsPerReq:默认值150在低并发情况下很好用,高并发情况下建议适当增大,来提升每个用户的生成速度,可以让用户先开始时多等一会。decodeTimeMsPerReq:建议固定为默认值50 ms,只修改prefillTimeMsPerReq来调整调度。
Batch参数:
maxQueueDelayMicroseconds:组建Batch的等待时间,默认值5000us在大并发下可以提升吞吐;但是在小规模并发下可能会导致等待,小规模情况下可以设置成500us。maxPrefillBatchSize和maxPrefillTokens:这两个参数都会影响Prefill Batch,maxPrefillTokens限制了Prefill中的总token数,maxPrefillTokens的默认值是8192,如果是4机部署BF16 671B的可以这么设置,防止内存溢出,但是如果4机W8A8 671B,建议直接设置到32k或64k,此时大量显存留给了kv cache,显存完全撑得住。maxPrefillBatchSize也是一样,如果资源少,请设置10或者以下;如果资源非常充足,可以大胆的扩展。maxBatchSize:Decode阶段的 Batch Size,默认值200实在太小,设置成512都行。如果4机W8A8 671B部署,资源很充足,设置4096都是毫无问题。maxIterTimes和maxSeqLen:会限制最大生成token数量,生成数量是maxIterTimes和maxSeqLen-inputLen取最小值。虽然默认值是512和2560,但这实在太小。如果是推荐的部署方案,可以大胆的设置成32k,然后根据你的内存情况慢慢增大,目前看来如果想扩展到R1的128k,需要限制住BatchSize和maxPrefillBatchSize。
性能测试
首先我得说下定性情况,使用更多的机器部署一个模型实例,在有限资源情况下将更多的显存留给用户的KV Cache是个更好的选择。这样可以大大提高吞吐量,让更多用户请求同时计算,保持服务的稳定、不会拥塞。虽然因为多机间传输、Batch较大导致生成速度略微降低,但是总比让用户排队体验更好吧。比如,用4台8卡机器运行W8A8的671B DeepSeek-R1,或者用8台机器运行BF16的671B DeepSeek-R1,支撑1000用户同时访问是没问题的。当然,如果你的计算资源非常充足,开多个实例用PD分离显然是个更好的选择。
相关概念和调度策略分析
推理流程分为两个阶段:
- Prefill阶段:计算用户输入所有token的相关性,这个阶段计算量很大,存在多个大矩阵相乘,是 compute bound 的。
- Decode阶段:每次生成新的一个token和之前的所有token的KV Cache计算相关性,随着token序列变长,KV Cache矩阵快速增长,这个阶段是 memory bound 的。从计算量上看,一个token和之前token计算相关性的计算量并没有达到算力瓶颈,大量参数、中间结果的IO反而占据了很多时延,此时需要大Batch Size来提高资源利用率。
这里对单模型推理更多计算量性能分析可以参考 LLM Roofline。
调度也分为两个层面:机器层面、请求层面。
机器层面: MindIE Server的调度将Prefill和Decode阶段分开,如果只有一个实例(PD融合部署),那么会动态调度计算Prefill或者Decode阶段。此时,系统配置中 prefillTimeMsPerReq 和 decodeTimeMsPerReq 起到了调度作用,调度算法非常工程化,根据用户设定的 prefillTimeMsPerReq 计算出预估的Prefill需要时间;同时根据decodeTimeMsPerReq计算出 Decode累积需要时间。如果Prefill需要时间 大于 Decode累积需要时间,则说明Decode积压,会Decode优先;否则Prefill优先。
- 🌟 根据这个调度策略,在配置不变的情况下,可以分析出调度趋势:当并发量较小的时候,会资源会优先倾斜给Prefill;当并发量较大的时候,资源会逐步向Decode倾斜。
请求层面: 同时,Prefill、Decode在请求到来时也有类似FCFS的调度策略,这主要是请求层面的,这部分可以参考 P/d-serve 论文,有详细测量数据。这里测试我直接简化让请求长度都一样,所以就不存在这部分调度,就不详细阐述了。
华为这相关技术的具体阐述应该是这一篇2024年8月的论文:P/d-serve。这个技术基于的是最早发布于2024年1月的 TetriInfer 方案。可以清晰看出华为对于PD调度技术的推进。
PD分离还有很多相关的技术,过段时间我在博客上写一个PD分离相关的简单综述,更加详细的阐述一下发展流程。
并发能力
先测试客户端不同并发访问量(Concurrency)的情况。测试环境:
- 模型:DeepSeek-R1 671B,W8A8
- 输入token:512;输出token:512
- 部署:4台机器,每台8卡910B,RoCE交换机连接
- maxPrefillTokens: 32768,这个设置小了点
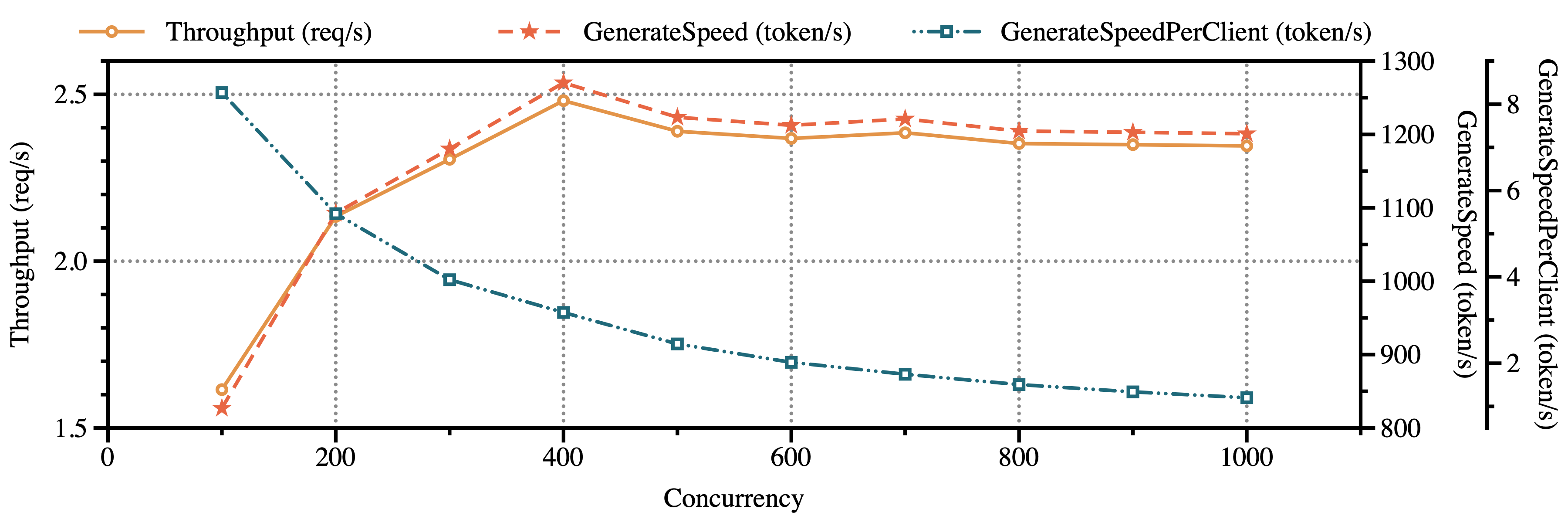
吞吐量: 首先测试吞吐量。下图展示平均吞吐量和生成速度。可以看到吞吐量和平均生成token速度的趋势是保持一致的,并且在并发量400左右达到瓶颈,后续增加并发也保持稳定。虽然服务端平均吞吐保持稳定,但是每个客户端的生成速度明显下降(8->1)。这是符合直觉的,并发量增大,每个客户端的生成速度相应降低了,同时服务端达到性能瓶颈保持稳定。
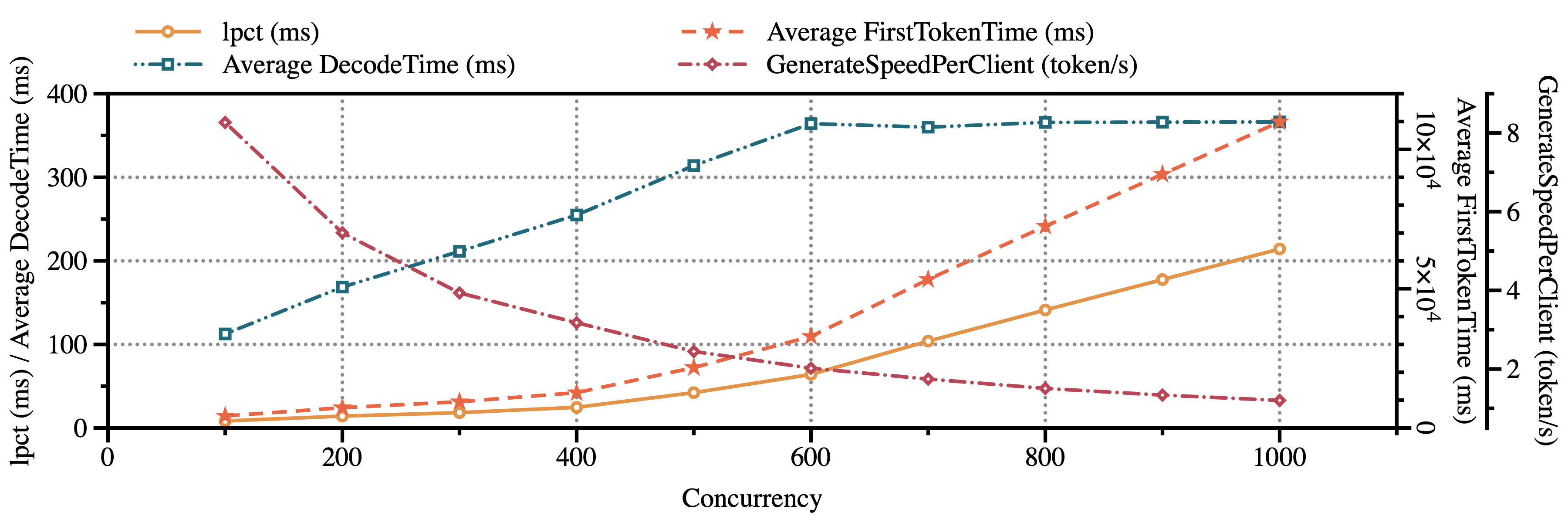
延迟: 再说延迟方面,结果如下图所示。lpct是首token总时延/输入总token数,单位 ms。因为这里输入总token数保持不变,所以lpct和First Token Time保持一致。同时,随着并发量上升,First Token Time的增长是先慢后快,而Decode Time是先快后平稳,这是符合我们之前的分析的,根据MindIE的调度策略 当并发量较小的时候,会资源会优先倾斜给Prefill;当并发量较大的时候,资源会逐步向Decode倾斜。 也就是说,400并发量前,First Token Time平稳,是偏向于Prefill的;400并发之后,Decode Time平稳,更偏向于Decode阶段。
其他时延: 测试的Tokenizer和Detokenizer的时延都比较平稳,Detokenizer的时延大概是Tokenizer的3~5倍,都在几毫秒级别。另一点是First Token Time和Decode Time的方差特别大,说明服务有点不稳定。
所以如果你也是4台机器每台8卡910B部署 W8A8 的 671B DeepSeek,显然并发量1000也可以稳稳撑住。但这个测试没有普遍性,因为还受到服务配置的影响,尤其是maxPrefillTokens等参数限制后,Prefill阶段Batch其实是会自动分组调度的,后面我再详细测试下不同配置、输入输出token数量差异很大情况下的结果。
部署流程
部署流程有个前几天刚出的文档:部署推理服务。 我是手动部署的,据说自动部署也很好用,后面会写一些坑。
- 最好同时阅读昇腾DeepSeek-R1模型库的文档,建议互相参考,其中包含一些错误处理。
- docker启动时,加上
--shm-size 500g防止内存溢出,有的文档里没有。 - 模型权重文件夹必须设置权限
chmod -R 750 {/path-to-weights},非常令人痛苦的教训。 - 查看报错日志: 如果老是崩溃实在找不到问题,可以自己找地方建立一个日志文件夹
your_path/plog,然后export ASCEND_WORK_PATH=your_path/plog到日志文件夹。运行完后,在your_path/plog/log/debug/plog/下执行grep "ERROR" ./*可以看到详细报错。 - 算子库报错日志: 这个相关的日志可参考昇腾DeepSeek-R1模型库的文档 的“日志收集”章节。
- 网络连接闪断: 如果实在不确定是否有网络链接问题,可以使用脚本测试通信算子,阅读文档。如果报错找不到MPI相关的动态链接库,可以加上
export LD_LIBRARY_PATH=/home/mpich/lib/:/usr/local/Ascend/ascend-toolkit/8.0.RC3/aarch64-linux/lib64:$LD_LIBRARY_PATH,请注意修改mpich的位置和ascend-toolkit/8.0.RC3的版本。
注意:文档里说的这一步检查物理链接,但是没说会输出什么,如果什么都没输出是不对的啊,正常的是有输出链接情况的!
# 检查物理链接
for i in {0..7}; do hccn_tool -i $i -lldp -g | grep Ifname; done
硬件双机背板直连的情况
我们用了多种部署方式,其中有个实例用了双机背板直连(2台8卡64G),有点坑需要单独处理。
因为检测工具需要检测网关正确:
# 查看网关是否配置正确
for i in {0..7}; do hccn_tool -i $i -gateway -g ; done
而直连没有网关,所以可以配置网关为每个GPU自己,方法:
# 设置第0张卡的网关为 192.168.11.100
hccn_tool -i 0 -gateway -s gateway 192.168.11.100
同时可以考虑将GPU检测对象设置为另一台机器的GPU IP,检测连通性,方法:
# 设置检测对象ip,设置第0张卡的检测对象 192.168.11.200
hccn_tool -i 0 -netdetect -s address 192.168.11.200
配置好后可以通过单独测试本机和另一台机器的GPU IP保证连通信:测试npu之间的连通性:使用 -netdetect 配置当前npu需要检测的另一个npu的地址,然后使用-net_health 来检测是否连接正常。如果成功会显示 net health status: Success 错误的话显示 net health status: Receive timeout。
# address是目标GPU IP
hccn_tool -i 0 -netdetect -s address ${adress}
别忘了TLS校验为0
# 检查NPU底层tls校验行为一致性,建议全0
for i in {0..7}; do hccn_tool -i $i -tls -g ; done | grep switch
# NPU底层tls校验行为置0操作
for i in {0..7};do hccn_tool -i $i -tls -s enable 0;done
参考:HCCN Tool接口文档。
四机部署的镜像问题
MindIE的T3.1镜像无法拉起32卡671B模型,同时会导致W8A8模型无法4机部署,但是可以支持W8A8模型2机部署,如果需要4机部署回退镜像版本。
服务化配置
服务化配置里有很多细致的参数需要设置,参考配置参数说明文档。写的挺详细的。
- 如果想对所有IP提供服务(不推荐,只是因为我们的服务器是独立内网,所以为了测试方便设置,正式服务时会关闭),设置
allowAllZeroIpListening为true,ipAddress为0.0.0.0。 - 配置文件中有个参数
maxIterTimes会限制最大生成token数量,记得修改,参考配置参数说明文档。 - 如果一直卡死拒绝服务,可以考虑设置
MaxSeqLen和maxPrefillTokens配置相同大小,可以规避重计算问题。 - 保险起见,可根据业务负载从小数值设置
maxPrefillBatchSize逐步增大,防止出现资源不足。 - 可开启电源高性能模式,参考说明文档,可以提升约20%性能。
后面我单独测试调度策略情况。
持续更新中……

Leave a Comment